
Apache Kafka〜OSSの分散メッセージングシステム〜
大規模なシステムを構築して運用する場合、複数のアプリケーションが出力した大量のデータを、複数のバックエンドソフトウェアで処理したい場合があります。そのようなプロジェクトの場合、規模に応じて複雑なデータフローが必要になります。複雑なデータフローになることで、管理が複雑化したり、処理に時間や制限がかかってしまったり、アプリケーションの負担が増えるなどの課題があります。ここでは、複雑なデータフローで起こりうる課題を解決するソリューション、OSSの分散メッセージングシステムApache Kafkaの特徴や活用方法を紹介します。
Apache Kafkaとは
Apache Kafkaとは、随時生成される膨大なデータをリアルタイムに処理することができる、オープンソースソフトウェアの分散メッセージングシステムです。イベントストリーミングサーバや、メッセージサーバとも呼ばれています。ストリーミング・データ、つまり、はっきりとした始まりや終わりのない継続的に生成される膨大な数のデータを収集や変換、処理するために使用されます。Apache Kafkaは、現在、Apache Software Foundationによって提供されており、Apache License v2ライセンスでOSSとして公開されています。Apache Kafkaは、JavaとScalaの言語を使って開発されており、公式のサイトでは多くのドキュメントやAPIの解説、開発者のコミュニティなどが掲載されています。また、クライアントライブラリが様々な言語で提供されています。
通常、アプリケーションへのリクエスト情報や、IoTのセンサーデータ、アクセスログなどのデバイスから生成されるストリームデータは、イベントやメッセージと呼ばれています。Apache Kafkaは、このメッセージの受け渡しを行う仲介役として機能します。Apache Kafkaを活用することで、1分間で数十億ものストリーミングイベントの処理を行うことができる分散型のアプリケーションを実現します。
Apache Kafkaの基本的な動作
Apache Kafkaを理解する上で、Apache Kafkaの動作について説明します。データの受け渡しには、以下の3つの役割をもつ主要なソフトウェアが存在します。
- Producer(プロデューサ):データを送信する側
- Consumer(コンシューマ):データを受信する側
- Broker(ブローカー):データの管理を行う(Apache Kafka)
この3つのソフトウェアは、下記のような関係性で利用されます。
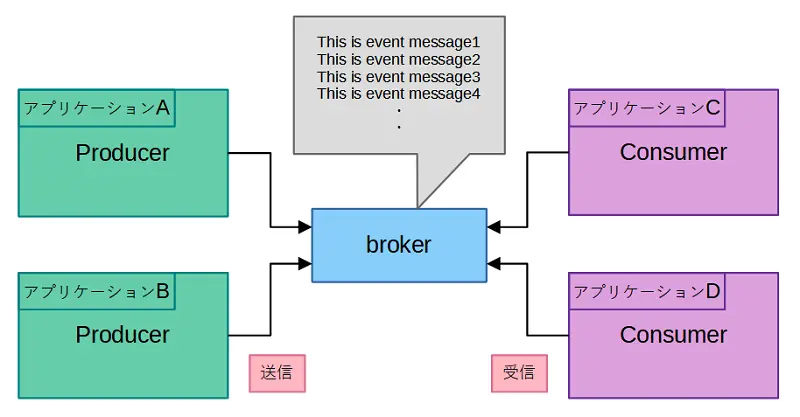
Producer(プロデューサ)は、Broker(ブローカー)にメッセージを配信し、Consumer(コンシューマ)は、Broker(ブローカー)にメッセージを取りに行きます。Broker(ブローカー)がメッセージを保持している限り、Consumer(コンシューマ)が追加されても同じメッセージを取得することができます。これが、Apache Kafkaが実装している基本的な機能になります。
Apache Kafkaの特徴
Apache Kafkaを利用してシステム間の通信を行うことで、以下のメリットがあります。
システムの疎結合を実現できる
複数のアプリケーションが出力したデータを、複数のバックエンドソフトウェアで処理したい場合、すべてのバックエンドソフトウェアに同じデータを保存しようとすると、複雑なデータフローが必要になります。そのような構成の場合、スケールアウトやメンテナンス時に、すべてのアプリケーションの設定を追加したり変更する必要が出てくるため、管理が複雑になります。また各アプリケーションの負荷が増えることにもなります。そこで、データの間を取持つBroker(ブローカー)の役割として、Apache Kafkaを配置します。その結果、多数のメッセージの出し入れの役割を、すべてApache Kafkaに統合し、代行させることができるようになります。以上のようにApache Kafkaの特徴の1つとして、高いスループット、拡張性に優れた設計として最適化され実装されているので、ユーザーの利用環境や要件に応じてシステム構築を提供することが可能です。
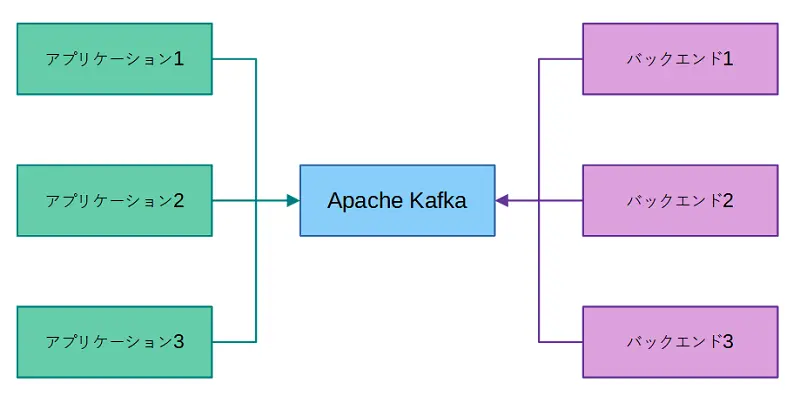
アプリケーションは、Apache Kafkaにデータを保存するのみになります。バックエンドもApache Kafkaからデータを取得するのみです。そのため、アプリケーション側もバックエンド側も、データ送受信の際に互いの影響を受けません。またApache Kafkaは、期間やサイズ以外の条件では、基本的にメッセージを削除しないため、すべてのバックエンドが一貫して迅速にメッセージを受け取ることができます。
さらに、Apache Kafkaは、どのConsumer(コンシューマ)がどこまでメッセージを読んだか、というオフセットの情報を保持しています。さらにConsumer(コンシューマ)をグループ化して、グループ別にオフセットを管理することも可能です。
処理性能を保ちながらデータを保全できる
メッセージサービスやキューサービスなどと呼ばれるソフトウェアの中には、メモリにデータを保存してやりとりを行うものが存在します。このようなソフトウェアは、サービスの再起動でメモリ上のデータが失われてしまうリスクがあります。Apache Kafkaは、データをディスクへ保存します。またApache Kafkaのクラスタリング機能により、複数のBroker(ブローカー)にデータを分散・複製することができます。このため、マシンの一部に障害が発生してもデータを失うことなく処理を継続することができます。そのため、処理性能を保ちながらデータを保全することや、障害に対する耐性を高めることが可能です。
Apache Kafkaの利用ケース
分散型のメッセージングシステムであるApache Kafkaのユースケースとして、主に以下のような例で使用されています。
- Webサイトのユーザアクティビティのトラッキング
ユーザの検索結果やページビューなどの動作を追跡し、リアルタイムにモニタリングすることができます。収集したデータを解析ソフトへ送信し、分析することでユーザ動向の調査を行うことができます。
- IoTなどのビックデータの処理
Apache Kafkaをメッセージブローカーとして利用することが可能です。Apache Kafkaは、スケーラビリティなソフトウェアで、スケールアウトが可能なため、IoTなどのビックデータの処理にも適しています。Kubernetesなどのコンテナ技術とも連携して利用されています。工場内の機械などのIoTデバイスや他の機器から、センサーデータを継続的にキャプチャして分析し、ビジネスの改善につなげることができます。
- ログの収集および集計
各システムから送られてくるデータを高速に集約することができるため、集まった情報をモニタリングすることができます。好きなタイミングでデータを受け取ることもできるため、ログの収集および集計に役立てることが可能です。
Apache kafkaのクラスタリング
複数台でクラスタリングが可能です。クラスタリングすることで、分散処理やデータのレプリケーションを行うことができます。
今まで、クラスタリングの方法として、元々はApache Software Foundation管理のZookeeperと呼ばれるソフトウェアを使っていました。しかし、Zookeeperを利用するアーキテクチャには次のような問題がありました。
- Kafkaの利用に必ずZookeeperが必要であるため、利用難易度が高い
- Zookeeperにより、複雑性が高まっている
- Zookeeper自体の処理性能に引っ張られるケースがある
このため、新しいKraftという方式のクラスタが実装されました。これはZookeeperを利用せず、Kafka単体でクラスタリングを行う仕組みです。Raftと呼ばれる分散合意アルゴリズムを採用しているのが特徴です。
Zookeeperを利用する場合、別途Zookeeperクラスタが3台必要です。Kraftを利用する場合も、推奨の構成はKraftのコントローラ3台とブローカ3台の構成です。ただ、Kraftの場合は、開発環境や小規模環境でコントローラとブローカを同居して利用することも可能です。このため、Kraftモードであれば、Kafkaクラスタは最低3台で構成できます。
デージーネットの取り組み
デージーネットでは、Apache Kafkaの基本的な機能を調査し、また、シングル構成のKafkaブローカのベンチマークを行いました。実際の利用には、お客様の利用するサービスに対応してパフォーマンスの調整が必要なため、今後は、他のシステムとの組み合わせを行い、ベンチマーク等を実行していきます。これらの結果は調査報告書よりご覧いただけます。システムを構築したところまでで終わらず、お客様の運用が続く限り、システム全体を見守り、お客様のご要望に対応することが私たちのポリシーです。
「情報の一覧」
Apache Kafka調査報告書
Apache Kafkaとは、イベントストリーミングサーバーや、メッセージサーバーと呼ばれるオープンソースのソフトウェアの1つです。少ないリソースで高速な動作が可能です。この記事は、インストールや利用方法の詳細について調査し、内容をわかりやすくまとめたものです。
ClickHouse〜高速に動作するデータベース管理システム〜
オンライン分析処理(OLAP)に利用できる、オープンソースの列指向データベース管理システム(DBMS)のClickHouseを紹介します。
NetFlowでネットワーク問題を解決〜OpenNFA〜
デージーネットではOSSを組み合わせ、低コストでネットワーク監視を導入することができる、Netflowを活用したトラフィック監視システム『OpenNFA(オープンエヌエフエー)』を開発しました。
デモのお申込み
もっと使い方が知りたい方へ
操作方法や操作性をデモにてご確認いただけます。使い方のイメージを把握したい、使えるか判断したい場合にご活用下さい。デモをご希望の方は、下記よりお申込みいただけます。
