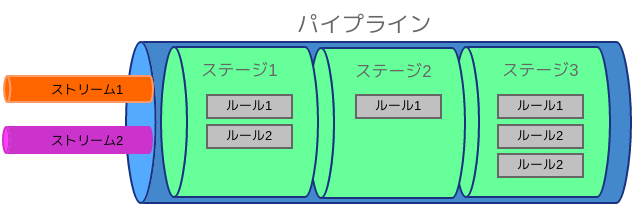
extractorでは、Graylogのインタフェースを使って、ログの分解などの設定を行うことができます。一方でpipelineには、そのようなインタフェースはありません。代わりに、Droolsと呼ばれるルールエンジンのルールを記述して、ログを操作します。
13.2. pipelineの作成
pipelineの設定は、メニューの Pipelines リンクから移動した画面で行います。

pipelineを作成するには、以下の順で設定を行います。
- ルールの作成
- ルールとステージの紐付け
- pipelineとstreamの紐付け
13.2.1. ルールの作成
pipelineを作成する前にまずルールの作成を行います。
ルールは、pipeline処理の基礎です。ルールを使うことで、ログメッセージの変更や値の追加・削除、streamの切り替えを行うことができます。
ルールの中で行う、条件の一致や値の操作などは関数で行われます。Graylogには、文字列変換やJSONや日付形式の解析、正規表現やGrokパターンによる値の比較を行うための関数が付属しています。
さらに関数はプラグインで追加可能です。
ルールの作成は、メニューの Manage rules リンクから移動した画面で行います。
Create Rule ボタンをクリックするとルールの作成画面に移動します。
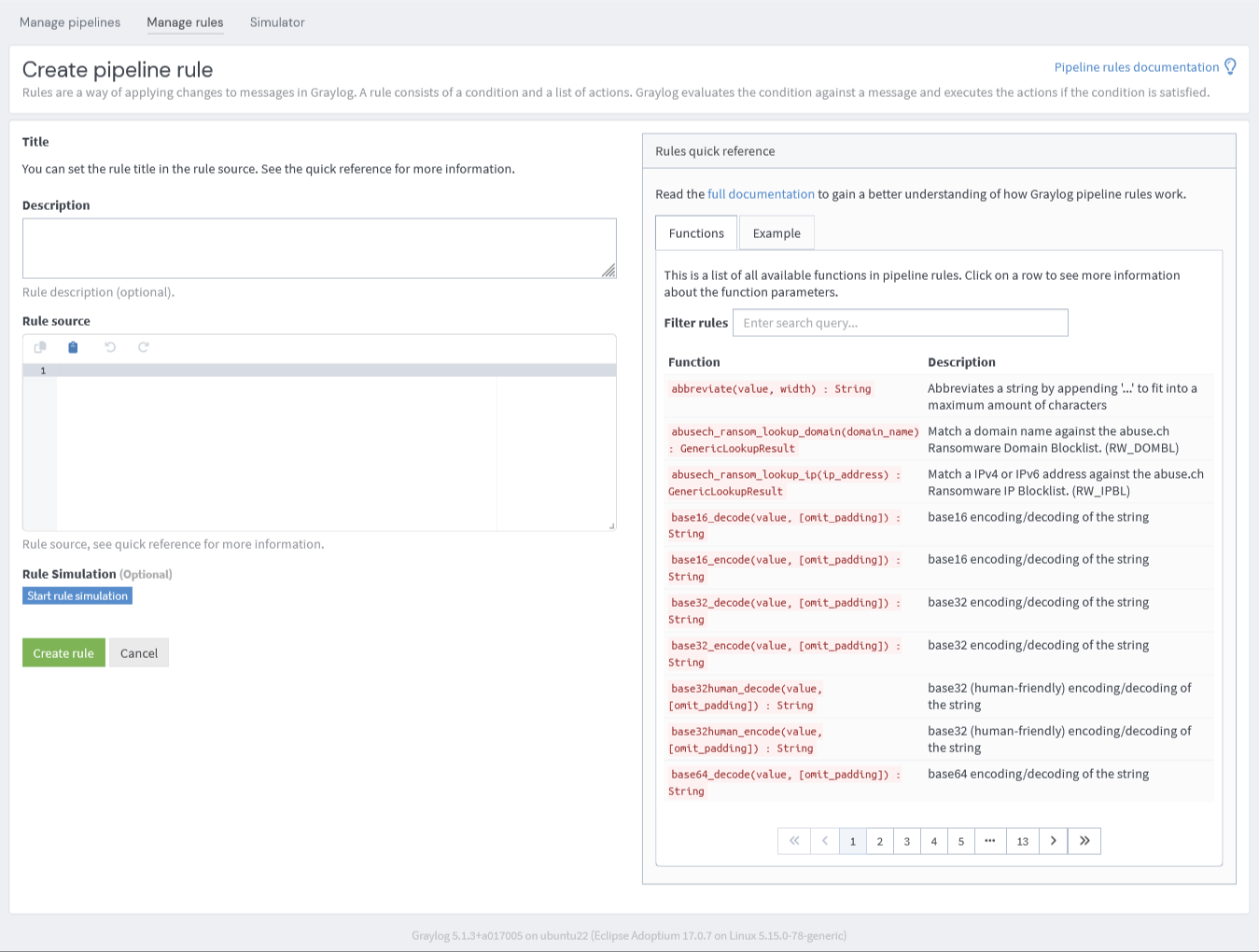
ルールの作成画面では、画面の左側が入力フォーム、右側が利用できる関数のリファレンスとルールの例になっています。
Description にはルールの説明を入力します。
Rule source については、以下で詳しく解説します。
13.2.2. ルールの定義
ルールの定義方法を次の例を使って解説します。
ルール1
rule "has firewall fields"
when
has_field("src_ip") && has_field("dst_ip")
then
end
ルール2
rule "from firewall subnet"
when
cidr_match("10.10.10.0/24", to_ip($message.gl2_remote_ip))
then
end
ルール3
rule "drop_message"
when
true
then
drop_message();
end
まず、 ルール1を見ていきます。
rule の行で、ルールの名前を定義しています。この名前はルール全体で一意である必要があります。また次の when-then の間では、ルールを適用する条件を定義しています。この条件は、 has_field 関数を使い、src_ipフィールドとdst_ipフィールドが存在するか検査しています。
続く then-end には何も記載がありませんが、本来であれば、この間には条件にマッチしたログに対するアクションが記載できます。条件のみを定義した場合、そのルールは、pipelineの次のステージに進むかどうかの検査を行う役割になります。このように条件を細分化しておくことで、後々同じようなルールのときに再利用できるメリットがあります。
ルール2もルール1と基本的な構造は変わりません。
ここでの重要な要素は以下のとおりです。
$message 変数を利用してフィールドの値を参照している
$message.gl2_remote_ip はgl2_remote_ipフィールドを参照する意味となる
to_ip 関数を使い文字列のIPアドレスをネットワークバイトオーダに変換しているcidr_match 関数を行い、上記で変換したIPアドレスのデータが10.10.10.0/24の中であるか検査している
ルール3は、アクションだけを実行するルールです。
when-then の間で true を記載することで、必ず条件に一致してアクションが実行されるようになります。アクションで行っていることは、 drop_message 関数を使い、メッセージを破棄しています。
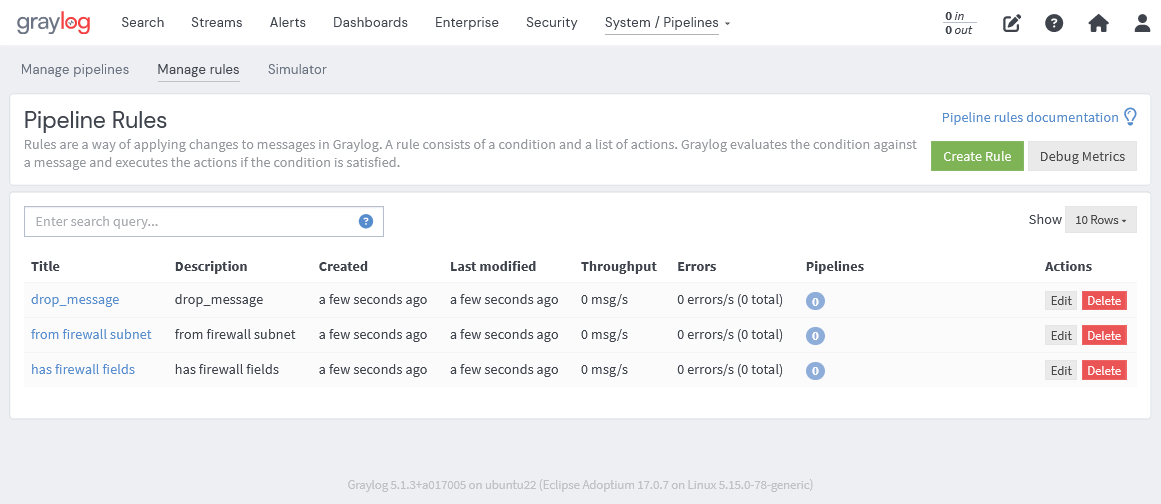
上記で解説したルールを作成すると次のように一覧が表示されます。
13.2.3. ルールとステージの紐付け
続いて、作成したルールをステージに紐づけしていきます。
ステージの設定を行うため、まずpipelineを作成します。
Manage pipelines タブを押し、 Add new pipeline をクリックします。
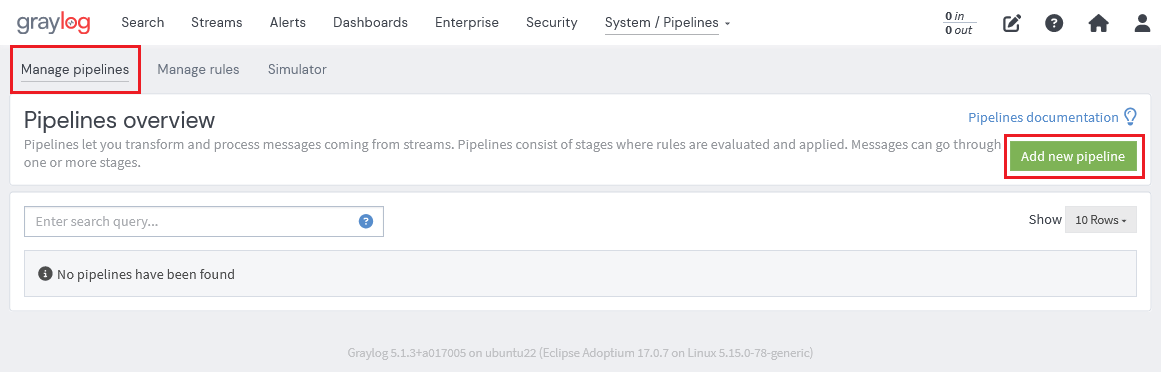
pipelineの title (タイトル) と Description (説明)を入力して新しいpipelineを作成します。
Create pipeline を押すと、pipelineが作成され、詳細画面が表示されます。

デフォルトでは、ステージ0のみ作成されます。
ステージを追加する場合は、 Add new stage のボタンをクリックします。
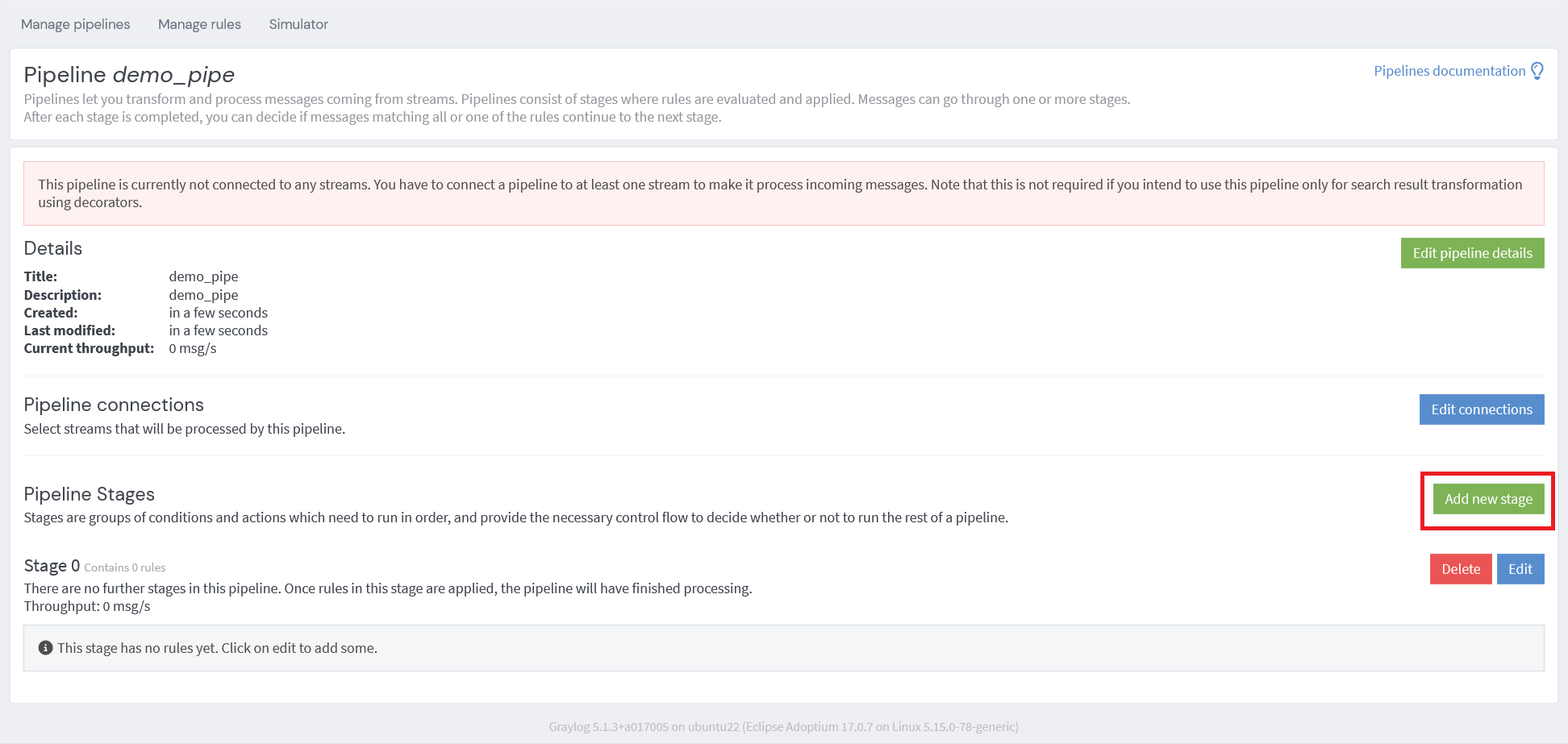
ステージの設定画面が表示されます。

入力項目は次の通りです。
Stage : ステージの優先順位を入力します。Continue processing on next stage when : 次のステージ進む条件を選択します。
All rules on this stage match the message : すべてのルールの条件が一致した場合のみ、次のステージに進むAt least one of the rules on this stage matches the message : どれかひとつのルールに一致した場合、次のステージに進むNone or more rules on this stage match : 一致するルールが一つも存在しない場合、次のステージに進む
Stage rules : 作成したルールを選択します。複数のルールを追加できます。
作成したルールをそれぞれステージ別に追加すると次のようになります。
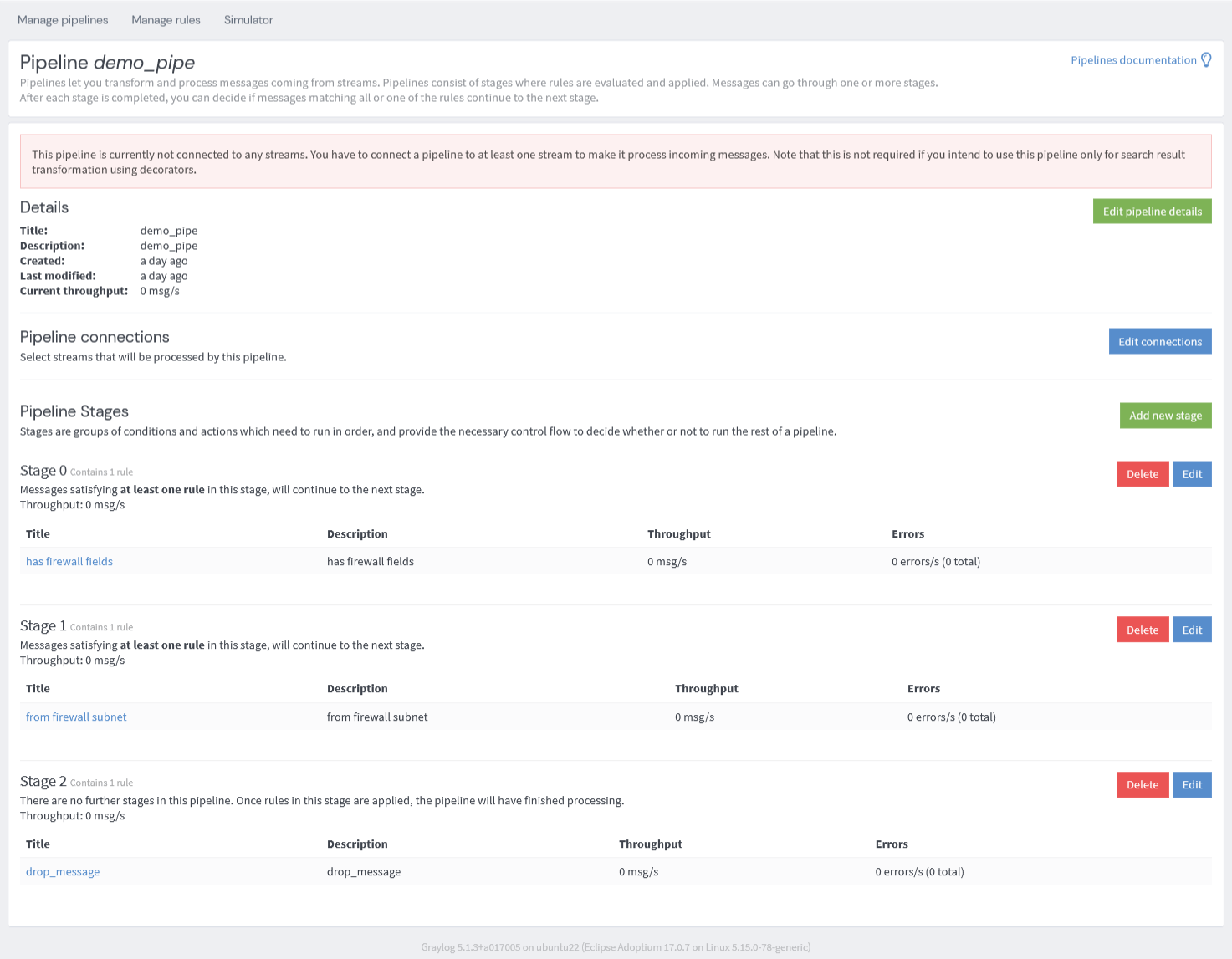
このpipelineの動きは以下の通りです。
- ステージ0で、src_ipなどのフィールドの存在検査をする
- ステージ1で、サブネットの範囲内であるかを検査する
- ステージ2で、メッセージを破棄する
つまり、ルールの組み合わせで値の検査を行い、条件にマッチしたログだけを破棄するというブラックリストの設定が行われました。
ただし、これだけではまだpipelineは動作しません。
pipelineとstreamの紐付けを行う必要があります。
13.2.4. pipelineとstreamの紐付け
Edit connections をクリックしてstreamを選択します。

この設定で、pipelineの処理が開始されます。
13.5. 関数詳細
13.5.1. debug
debug(value: any)
渡された値を文字列としてGraylogログに出力します。
デバッグメッセージは、デバッグしようとしているメッセージを処理しているGraylogノードのログにのみ表示されます。
debug(例)
// Print: "INFO : org.graylog.plugins.pipelineprocessor.ast.functions.Function - PIPELINE DEBUG: Dropped message from <source>"
let debug_message = concat("Dropped message from ", to_string($message.source));
debug(debug_message);
13.5.2. to_bool
to_bool(value: any)
文字列値を使用して、単一のパラメータをブール値に変換します。
13.5.3. to_double
to_double(value: any, [default: double])
最初のパラメーターをdouble浮動小数点値に変換します。
13.5.4. to_long
to_long(value: any, [default: long])
最初のパラメータをlong整数値に変換します。
13.5.5. to_string
to_string(value: any, [default: str])
最初のパラメータを文字列表現に変換します。
13.5.6. to_url
to_url(url: any, [default: str])
文字列表現を使用して値を有効なURLに変換します。
13.5.7. to_map
to_map(value: any)
指定されたマップのような値を有効なマップに変換します。
この関数は、現在解析されたJSONツリーのマップへの変換のみをサポートしています。そのため set_fields と一緒に使用できます。
to_map(例)
let json = parse_json(to_string($message.json_payload));
let map = to_map(json);
set_fields(map);
13.5.8. is_null
is_null(value: any)
値がnullかどうかをチェックします。
13.5.9. is_not_null
is_not_null(value: any)
値が nullでないかどうかをチェックします。
13.5.10. is_boolean
is_boolean(value: any)
値がbool値( true または false )かどうかをチェックします。
13.5.11. is_number
is_number(value: any)
値が数値かどうかをチェックします。
13.5.12. is_double
is_double(value: any)
値が浮動小数点値かどうかをチェックします。
13.5.13. is_long
is_long(value: any)
値が整数値かどうかをチェックします。
13.5.14. is_str
is_str(value: any)
値が文字列かどうかをチェックします。
13.5.15. is_collection
is_collection(value: any)
値が反復可能なコレクションかどうかをチェックします。
13.5.16. is_list
is_list(value: any)
値が反復可能なリストかどうかをチェックします。
13.5.17. is_map
is_map(value: any)
値がマップかどうかをチェックします。
13.5.18. is_date
is_date(value: any)
値が日付かどうかをチェックします。
13.5.19. is_period
is_period(value: any)
値が期間かどうかをチェックします。
13.5.20. is_ip
is_ip(value: any)
値がIpアドレスかどうかをチェックします。
13.5.21. is_json
is_json(value: any)
値が解析済みのJSONツリーかどうかをチェックします。
13.5.22. is_url
is_url(value: any)
値が解析済みのURLかどうかをチェックします。
13.5.23. abbreviate
abbreviate(value: str, width: long)
ellipsesを使用して文字列を省略します。
13.5.24. capitalize
capitalize(value: str)
最初の文字を大文字にします。
13.5.25. uncapitalize
uncapitalize(value: str)
最初の文字を小文字にします。
13.5.26. uppercase
uppercase(value: str, [locale: str])
大文字に変換します。
localeのデフォルトはenです。
13.5.27. lowercase
lowercase(value: str, [locale: str])
小文字に変換します。
localeのデフォルトはenです。
13.5.28. swapcase
swapcase(value: str)
大文字と小文字を入れ替えます。
13.5.29. contains
contains(value: str, search: str,
[ignore_case: boolean])
valueにsearchが含まれているかどうかをチェックし、オプションで検索パターンの大文字と小文字を無視します。
13.5.30. replace
replace(value: str, search: str,
[replacement: str], [max: long])
指定した文字列を入れ替えます。
max は入れ替える個数を指定できます。 max が2の場合は、先頭からマッチした2つの文字列が指定した文字列に入れ替わります。デフォルトは -1 でマッチした文字列をすべて入れ替えます。
replace(例)
let new_field = replace(to_string($message.message), "oo", "u"); // "fu ruft uta"
let new_field = replace(to_string($message.message), "oo", "u", 1); // "fu rooft oota"
13.5.31. starts_with
starts_with(value: str, prefix: str,
[ignore_case: boolean])
文字列 value が指定された prefix で始まるか検査します。
オプションで大文字小文字を区別するか指定することができます。
starts_with(例)
// Returns true
starts_with("Foobar Baz Quux", "foo", true);
// Returns false
starts_with("Foobar Baz Quux", "Quux");
13.5.32. ends_with
ends_with(value: str, prefix: str,
[ignore_case: boolean])
文字列 value が指定された prefix で終わるか検査します。
オプションで大文字小文字を区別するか指定することができます。
ends_with(例)
// Returns true
ends_with("Foobar Baz Quux", "foo", true);
// Returns false
ends_with("Foobar Baz Quux", "Quux");
13.5.33. substr
substr(value: str, start: long, [end: long])
startオフセット(ゼロベースのインデックス)から始まるvalue部分文字列を返します。オプションでendオフセットを指定できます。
13.5.34. concat
concat(first: str, second: str)
firstとsecondテキストを結合した新しい文字列を返します。
13.5.35. split
split(pattern: str, value: str, [limit: int])
pattern文字列で、strを分割します。limitオプションを指定することで、分割する回数を指定できます。
パターンは有効な Java文字列リテラル でなければなりません。正規表現でバックスラッシュをエスケープしてください。
13.5.36. regex
regex(pattern: str, value: str,
[group_names: array[str])
patternの正規表現とvalueが一致するか検査します。
正規表現でグルーピングしている場合、groupe_namesオプションの配列を使用してグループ名をつけられます。
名前がつけられていない場合、グループ名を0で始まる文字列です。
13.5.37. regex_replace
regex_replace(pattern: str, value: str,
replacement: str, [replace_all: boolean])
pattern の正規表現と value が一致した場合に指定した文字列と入れ替えます。
replace_all に true を指定した場合、マッチしたすべての文字列が入れ替わります。
13.5.38. grok
grok(pattern: str, value: str,
[only_named_captures: boolean])
Grokパターンpatternをvalueに適用します。
only_named_capturesだけをtrueに設定すると、名前付きキャプチャを使用して一致を返すことができます。
13.5.39. key_value
key_value(
value: str,
[delimiters: str],
[kv_delimiters: str],
[ignore_empty_values: boolean],
[allow_dup_keys: boolean],
[handle_dup_keys: str],
[trim_key_chars: str],
[trim_value_chars: str]
)
指定されたvalueからキーと値の北亜を抽出し、フィールド名と値のマップとして返します。オプションで以下を指定することができます。
delimiters
kv_delimiters
- キーと値を区切るために使用される文字。デフォルト値: =
ignore_empty_values
- 空の値を許可するかどうか。デフォルト値: true
allow_dup_keys
- 重複キーを許可するかどうか。デフォルト値: true
handle_dup_keys
- take_firstを指定すると重複したキーの最初を採用します。
- take_lastを指定すると重複したキーの最後を採用します。
- ","などを指定すると、キーの値が,で結合されます。
- デフォルト値: take_first
trim_key_chars
trim_value_chars
Note
key_value関数の実行結果をkey_value引数として渡して、抽出されたフィールドをメッセージに設定することができます。
13.5.40. crc32
crc32(value: str)
CRC32ダイジェストを作成します。
13.5.41. crc32c
crc32c(value: str)
CRC32C(RFC 3720、セクション12.1)ダイジェストを作成します。
13.5.42. md5
md5(value: str)
MD5ダイジェストを作成します。
13.5.43. murmur3_32
murmur3_32(value: str)
MurmurHash3(32ビット)ダイジェストを作成します。
13.5.44. murmur3_128
murmur3_128(value: str)
MurmurHash3(128ビット)ダイジェストを作成します。
13.5.45. sha1
sha1(value: str)
SHA1ダイジェストを作成します。
13.5.46. sha256
sha256(value: str)
SHA256ダイジェストを作成します。
13.5.47. sha512
sha512(value: str)
SHA512ダイジェストを作成します。
13.5.48. parse_json
parse_json(value: str)
JSON文字列をJSONツリーオブジェクトに変換します。
13.5.49. select_jsonpath
select_jsonpath(json: JsonNode,
paths: Map<str, str>)
指定されたpathsをjsonツリーに対して評価し、結果の値のマップを返します。
13.5.50. to_ip
to_ip(ip: str)
指定されたip文字列をIpAddressオブジェクトに変換します。
13.5.51. cidr_match
cidr_match(cidr: str, ip: IpAddress)
指定されたipアドレスオブジェクトがcidrパターンと一致するかどうかを確認します。
13.5.53. route_to_stream
route_to_stream(id: str |
name: str, [message: str],
[remove_from_default: boolean])
messageを指定されたstreamにルーティングします 。 streamは、nameまたはidで指定できます。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
remove_from_defaultがtrue場合、メッセージはデフォルトstream "All messages"からも削除されます。
13.5.54. remove_from_stream
remove_from_stream(id: str | name: str,
[message: str])
messageを指定されたstreamから削除します 。 streamは、nameまたはidで指定できます。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
削除した結果、メッセージがすべてのstreamから外れた場合、デフォルトstream "All messages"に戻されます。
明示的に完全な削除をしたい場合、drop_messages関数を使用します。
13.5.55. create_message
create_message([message: str], [source: str],
[timestamp: DateTime])
指定されたパラメータから新しいメッセージを作成します。
いずれかが省略された場合、その値は現在処理中のメッセージの対応するフィールドから取得されます。
timestampが省略された場合、作成されたメッセージのタイムスタンプはその時点のタイムスタンプになります。
13.5.56. clone_message
clone_message([message: str])
メッセージをクローンします。 messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.57. drop_message
drop_message(message: str)
処理pipelineは、ルールの実行が終了した後に、指定されたmessageを削除します。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.58. has_field
has_field(field: str, [message: str])
指定されたmessageにfieldが含まれているかどうかを確認します。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.59. remove_field
remove_field(field: str, [message: str])
指定されたmessageから指定されたfieldを削除します。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.60. set_field
set_field(field: str, value: any,
[prefix: str], [suffix: str], [message: str])
指定されたfieldにvalueを設定します。fieldは有効な文字列でなければならず、 .を含むことはできません。
先頭と末尾の空白は削除されます。
オプションのprefixおよびsuffixパラメータは、挿入されたフィールド名に追加する接頭辞または接尾辞を指定します。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.61. set_fields
set_fields(fields: Map<str, any>,
[prefix: str], [suffix: str], [message: str])
指定されたメッセージのfieldに、指定された名前と値のペアをすべて設定します。
これは、 set_fieldのように機能する便利な関数です 。
オプションのprefixおよびsuffixパラメータは、挿入されたフィールド名に追加する接頭辞または接尾辞を指定します。
messageが省略された場合、この関数は現在処理中のメッセージを使用します。
13.5.62. rename_field
rename_field(old_field: str,
new_field: str, [message: str])
指定されたメッセージのフィールド名old_fieldをnew_fieldに変更します。
値は変更されません。
13.5.63. syslog_facility
syslog_facility(value: any)
syslogファシリティ番号valueを文字列表現に変換します。
13.5.64. syslog_level
syslog_level(value: any)
syslogレベルvalueを文字列表現に変換します。
13.5.65. expand_syslog_priority
expand_syslog_priority(value: any)
syslog優先順位番号を数値重大度とファシリティ値に変換します。
13.5.66. expand_syslog_priority_as_str
expand_syslog_priority_as_str(value: any)
syslog優先度番号を重大度およびファシリティ文字列表現に変換します。
13.5.67. now
now([timezone: str])
現在の日付と時刻を返します。 デフォルトのタイムゾーンUTC使用します。
13.5.68. parse_date
parse_date(value: str, pattern: str,
[locale: str], [timezone: str])
patternを使用して、 valueを日付と時刻のオブジェクトに変換します 。
パターンでタイムゾーンが検出されない場合は、オプションのtimezoneパラメータが想定されるタイムゾーンとして使用されます。
省略すると、タイムゾーンのデフォルトはUTCになります。
| 記号 |
意味 |
形式 |
例 |
|---|
G |
era |
text |
AD |
C |
century of era (>=0) |
number |
20 |
Y |
year of era (>=0) |
year |
1996 |
x |
weekyear |
year |
1996 |
w |
week of weekyear |
number |
27 |
e |
day of week |
number |
2 |
E |
day of week |
text |
Tuesday; Tue |
y |
year |
year |
1996 |
D |
day of year |
number |
189 |
M |
month of year |
month |
July; Jul; 07 |
d |
day of month |
number |
10 |
a |
halfday of day |
text |
PM |
K |
hour of halfday (0~11) |
number |
0 |
h |
clockhour of halfday (1~12) |
number |
12 |
H |
hour of day (0~23) |
number |
0 |
k |
clockhour of day (1~24) |
number |
24 |
m |
minute of hour |
number |
30 |
s |
second of minute |
number |
55 |
S |
fraction of second |
millis |
978 |
z |
time zone |
text |
Pacific Standard Time; PST |
Z |
time zone offset/id |
zone |
-0800; -08:00; America/Los_Angeles |
' |
escape for text |
delimiter |
|
'' |
single quote |
literal |
' |
13.5.69. flex_parse_date
flex_parse_date(value: str,
[default: DateTime], [timezone: str])
Natty日付パーサを使用して日付と時刻のvalueを解析します。
パターンでタイムゾーンが検出されない場合は、オプションのtimezoneパラメータが想定されるタイムゾーンとして使用されます。 省略すると、タイムゾーンのデフォルトはUTCになります。
13.5.70. parse_unix_millisecounds
parse_unix_millisecounds(value: long)
valueをUNIXミリ秒のタイムスタンプ(milliseconds since 1970-01-01T00:00:00.000Z)を使用して、 valueを日付と時刻のオブジェクトに変換します 。
13.5.72. to_date
to_date(value: any, [timezone: str])
valueを日付に変換します。 timezoneが指定されていない場合、デフォルトはUTCです。
13.5.73. years
years(value: long)
valueの年数でピリオドを作成します。
13.5.74. months
months(value: long)
valueの月数で月を作成します。
13.5.75. weeks
weeks(value: long)
valueの週数でピリオドを作成します。
13.5.76. days
days(value: long)
valueの日数でピリオドを作成します。
13.5.77. hours
hours(value: long)
valueの時間数でピリオドを作成します。
13.5.78. minutes
minutes(value: long)
valueの分数のピリオドを作成します。
13.5.79. seconds
seconds(value: long)
valueの秒数でピリオドを作成します。
13.5.80. millis
millis(value: long)
ミリ秒のvalue持つピリオドを作成します。
13.5.81. period
period(value: str)
valueからISO 8601で適宜された期間を解析します。
13.5.82. lookup
lookup(lookup_table: str, key: any,
[default: any])
名前付きルックアップテーブルで複数の値を検索します。
13.5.83. lookup_add_string_list
lookup_add_string_list(lookup_table, key, value,
[keep_duplicates])
名前付きルックアップテーブルに文字列リストを追加します。成功した場合は更新されたリストを返し、失敗した場合はnullを返します。
13.5.84. lookup_clear_key
lookup_clear_key(lookup_table, key)
名前付きルックアップテーブルのキーを削除します。
13.5.85. lookup_remove_string_list
lookup_remove_string_list
(lookup_table, key, value)
名前付きルックアップテーブルから指定された文字列リストのエントリを削除します。成功した場合は更新されたリストを返し、失敗した場合はnullを返します。
13.5.86. lookup_table_set_string_list
lookup_set_string_list(lookup_table, key, value)
名前付きルックアップテーブルに文字列リストを設定します。成功した場合は新しい値、失敗した場合はnullを返します。
13.5.87. lookup_set_value
lookup_set_value(lookup_table, key, value)
名前付きルックアップテーブルに単一の値を設定します。成功した場合は新しい値、失敗した場合はnullを返します。
13.5.88. lookup_string_list
lookup_string_list(lookup_table, key, [default])
名前付きルックアップテーブルで文字列リストを検索します。
13.5.89. lookup_value
lookup_value(lookup_table: str,
key: any, [default: any])
名前付きルックアップテーブルで単一の値を検索します。