
OpenSearch〜Elasticsearchをベースとした全文検索エンジン〜
OpenSearchとは、OpenSearch projectのもとElasticsearchをベースに開発された全文検索エンジンです。ビッグデータ等の大量のデータ等の検索や解析を高速に行うことができます。このページでは、OpenSearchの開発経緯、OpenSearchの特徴、Elasticsearchとの互換性について紹介します。
- +
目次
OpenSearchとは
OpenSearchログイン画面
OpenSearchとは、高速検索が可能な全文検索・分析エンジンです。OpenSearch projectによって、Apache License 2.0のライセンスで公開されています。OpenSearchは、Elasticが開発したElasticsearch7.10.2をフォークして作成されました。OpenSearchは、検索速度や分析柔軟性に優れており、わかりやすく検索機能を利用できます。またデータ蓄積や分析環境を簡単に構築することができます。そのため、ビッグデータを利用する場合等の大規模なシステムに向いている検索エンジンです。
OpenSearchの開発経緯
Elasticsearchは、2021年2月リリースのバージョン7.11.0以降、Server Side Public License(SSPL)と ElasticLicense 2.0(ELv2)のデュアルライセンスに移行しました。これにより、Elasticsearchがオープンソースソフトウェアでなくなってしまったため、第三者へ提供することが困難となりました。AWS 社は、Elasticsearchをつかったサービスを提供していたことや、ひとつのベンダーにロックインしてしまう状況を避けるため、ライセンス変更前のElasticsearchをベースとしたOpenSearchの開発を開始しました。そして、AWS 社は、Amazon OpenSearch ServiceというOpenSearchを利用したサービスを提供しています。
OpenSearchの特徴
ここからは、OpenSearchの特徴について紹介します。
ビッグデータ解析に向いている
OpenSearchは、列指向のデータ管理、FST、BKD-Treeによって、少ないメモリで高速な検索を実現しています。
列指向のデータ管理
リレーショナルデータベースでは行指向でデータを管理するのに対して、OpenSearchは、列指向でデータを管理します。製品の名前、仕入価格、販売価格、在庫数を管理するデータベースから在庫数が少ないものを抽出する場合を例にとってみます。
従来の行指向のデータベースでは、一つ一つの製品ごとにデータが管理されています。各製品の行の中から、在庫数の項目を取り出して比較することになります。一方、OpenSearchの列指向のデータ管理の場合には、データは列ごとに管理されています。そのため、在庫データの列の中から条件に合致するものだけを取り出して、関連する製品の名前を調べることができます。そのため、このような用途では、行指向のデータベースよりも、列指向のデータベースの方が適しています。
OpenSearchは、列指向でデータを管理するため、大量の情報の中から必要なデータを高速に検索することができるのです。
FST(Finite State Transducers)
OpenSearchは、テキストデータの管理にも高速な手法を採用しています。OpenSearchは、Apache Luceneが採用しているFST(Finite State Transducers)と呼ばれる検索インデックスを踏襲しています。FSTは、自然言語処理で使われる手法で、自然言語処理とは、人間の言語を機械で処理し内容を抽出することをいいます。テキストの正規化や品詞分類などでも使われます。OpenSearchは、FSTを採用することで、入力された文字列を正規化してインデックスします。
BKD-Tree
OpenSearchは、数値データの管理にも高速な手法を採用しています。OpenSearchは、数値データをBKD-Treeというアルゴリズムで管理します。BKD-Treeは、K-D-B-tree(K-dimensional B-tree)を改良したアルゴリズムです。B-treeは、コンピュータプログラムで検索を行う時によく使われる木構造のことです。K-D-B-treeは、それを多次元に拡張したアルゴリズムで、k次元のB-treeを意味しています。
OpenSearchは、BKD-Treeを採用することで、多様な数値データを高速に検索することができるようになっています。
検索機能が豊富
OpenSearchは、全文検索用データベースと考えられています。しかし、テキストだけでなく、数値、構造化データ、非構造化データ、地理情報などにも対応しています。
検索画面
OpenSearchでは、様々な検索クエリをサポートしています。次のような検索クエリの実行が可能です。
- 部分一致検索(match)
部分一致検索です。複数のキーワードを並べた場合にはOR検索します。
- AND検索(bool)
matchを使った複数の検索をAND条件で検索します。
- フレーズ検索(match_phrase)
空白を含む単語を検索します。
- 重み付け(boost)
複数のキーワードで検索する時に、検索時のパラメータとして重みを付けます。
- 範囲指定(filter)
範囲を指定して、該当するものだけを出力します。
- 検索スコア(explain)
検索結果にスコアつけて出力します。関連性の高さを調べることができます。
- highlight
検索に一致した部分に強調タグを付けて出力します。
クラスタ構成が可能
OpenSearchでは、物理的なデータを複数のノードに分散し、シャードをレプリケーションすることで、データの冗長性を確保することができます。クラスタをノード単位で構成しているため、クラスタの構築が容易に行えます。クラスタ構成を組みたいネットワークを指定し、同一クラスタ名で起動するだけで容易にクラスタ構成を組むことができるのです。このため、mysqlなどのRDBよりも、dockerやKubernetesのようなコンテナ環境で利用するにも適しています。また、大規模なデータの分散並列処理を行うHadoopなどとの連携が可能です。分散並列処理を行うことで大規模データの処理にも対応できます。
高速にデータの登録ができる
OpenSearchは、リレーショナルデータベースのようなスキーマを使わずに、データを登録することができます。データの型は自動的に判別されます。そのため、高速にデータの登録ができます。一方で、OpenSearchでは追加で明示的にスキーマの定義を行うことも可能です。そして、適切にスキーマを定義することで、より高い検索性能を引き出すことができます。OpenSearchでは、投入したデータに対して、事後的にスキーマの適用や修正を行うこともできます。
スケーラビリティ
大規模データに対応するために全文検索の処理やデータ配置を分散することができます。また、システムを拡張する時は、システムを停止することなくサーバを追加できます。導入時はスモールスタートで始め、利用者が増えてきたらサーバを追加するというようにシステム拡張を容易に行なうことができます。サーバを追加した時、データは自動的に各サーバに分散して再配置されます。
アクセス権限が可能
OpenSearchでは、ユーザにアクセス権限を付与することができます。そして、ユーザごとにインデックスやドキュメントなど、細かくデータベースへのアクセスを制限することが可能です。そのため、不正利用を防ぎ、安全にデータを管理することができます。また、マルチテナントのデータベースとして利用することもできます。
データ調査・可視化するためのツールがある
Elasticsearchの場合、Kibanaというログデータの可視化ツールを利用して抽出したデータをグラフィカルに表示していました。OpenSearchでは、Kibanaをベースとして作成されたOpenSearch Dashboardsが存在します。 OpenSearch Dashboardsにより、OpenSearch内のデータを調査・可視化することができます。
OpenSearch Dashboards
REST APIを備えている
OpenSearchは、REST APIを使用して他のシステムと連携することが可能です。ここでは、Logstash、Fess、Graylogとの連携について紹介します。
Fess
Fessは、OSSの全文検索エンジンです。ファイルサーバ検索やWebサイトの検索エンジンとして利用することができます。そのバックエンドとしてOpenSearchを使用することが可能です。FessとOpenSearchを連携することによって、全文検索の結果を瞬時に表示するということを実現しています。また、規模に応じてサーバの台数を増やすなどして、全文検索システムのスケールアウトも可能です。
Fessの検索結果画面
Logstash
Logstashは、様々な形式のデータを収集・変換し、任意の場所に保管することができるOSSです。Logstashを利用すると、ログファイルに溜まっているデータを解析して、データベースへ格納するなど、用途にあった形にデータを変換・保存することができます。Logstashを使って様々なデータを取得・収集し、OpenSearchに登録し、OpenSearch Dashboardsを使って可視化することができます。
Graylog
Graylogとは、GUIからログサーバの管理やログの参照、検査、可視化などを行うことができるOSSの統合ログ管理ソフトウェアです。GraylogもバックエンドとしてOpenSearchを使用することができます。大量のログを高速に検索することができるため、各種デバイスやソフトウェアから出力されるログを集中管理することができます。
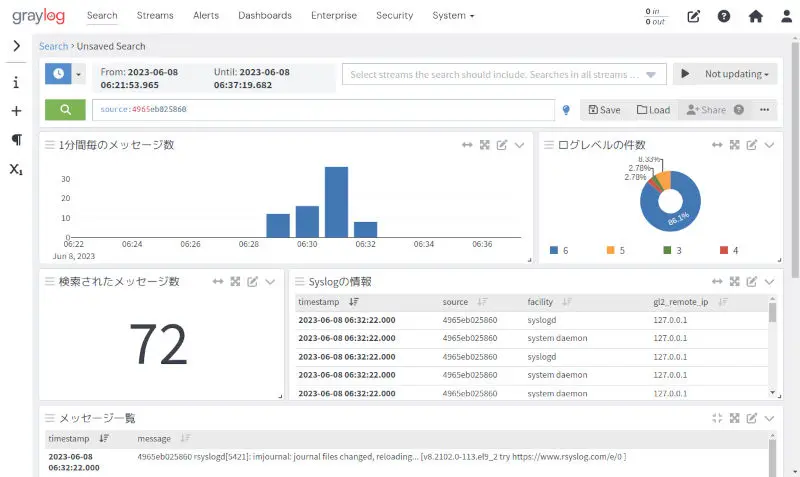
Graylog利用画面
Elasticsearchとの互換性
OpenSearchは、Elasticsearchをフォークして作成されているためElasticsearchと似た機能が存在します。しかし、OpenSearchとElasticsearchでは、一部互換性がなくなっています。そのため、OpenSearchへデータを投入したい場合は、投入するツールがOpenSearchに対応しているか確認する必要があります。
「Elasticsearch〜ビッグデータに対応した全文検索エンジン〜」へ
デージーネットの取り組み
デージーネットでは、OpenSearchを利用した全文検索エンジンシステムの構築および保守サービスをおこなっています。弊社でシステムの構築をしたお客様には、Open Smart Assistanceという保守サービスに加入することができます。OSSそのものではなく、運用中のシステムが適切に運用できることをサポートしています。 保守サービスでは、使い方から運用方法まで幅広い範囲でのQ&Aや、適正に運用できるようなセキュリティの情報提供、障害調査、回避を行い、安心して利用して頂けるよう管理者の業務をサポートします。OpenSearchのインストール方法や詳細な情報は、OpenSearch調査報告書に掲載されています。
「情報の一覧」
OpenSearch調査報告書
OpenSearchは、高速検索が可能な全文検索・分析エンジンです。「ドキュメント」と呼ばれるJSON形式のデータを各「インデックス」内に格納し、検索対象とします。本書は、OpenSearchについて調査した内容をまとめたものです。
Elasticsearch〜ビッグデータに対応した全文検索エンジン〜
Elasticsearchとは、IoTデータやビッグデータの解析などに使われるオープンソースの全文検索エンジンです。Elasticsearchは、大容量のデータでも高速に検索することができます。Kibanaなどの分析ツールと組み合わせて使用されます。
Fess〜全文検索システムのOSS〜
OSSの全文検索システムFessを利用するとどんなことができるのか、どんなところが優れているのかを紹介します。また、Fessについてデージーネットの行っているサービスやサポートについても紹介します。
統合ログ管理・監視のOSS〜Graylog〜
Graylogとは、GUIからログサーバの管理やログの参照、検査、可視化などを行うことができる統合ログ管理ソフトウェアです。ログ以外の各種の情報も蓄積してグラフ化したり、監視を行うこともできます。そのため、大量のデバイスを扱うIoTの分野でも活用されています。
parsedmarc〜DMARCレポート解析ツール〜
DMARCとは、電子メールにおける送信ドメイン認証技術の一つです。今回は、DMARCの設定を確認することができるDMARCレポート解析ツールparsedmarcを紹介します。
全文検索エンジンとは?おすすめOSS比較3選
全文検索エンジンは、膨大なデータベース内のテキストを瞬時に横断検索し、情報を迅速に探し出すことができます。本記事では、OSSの全文検索エンジン比較、選定ポイントを詳しく解説します。
【Webセミナー】検索時間を削減!OSSの全文検索システムFess紹介セミナー
| 日程: | 4月17日(木)Webセミナー「BigBlueButton」を使用します。 |
| 内容: | 「欲しいファイルが見つからない…」「ファイルの保管場所を知りたい…」という課題はありませんか?このセミナーでは、社内にある欲しい情報の検索時間を削減できるOSSの全文検索システムを紹介します。 |
| ご興味のあるかたはぜひご参加ください。 | |

デモのお申込み
もっと使い方が知りたい方へ
操作方法や操作性をデモにてご確認いただけます。使い方のイメージを把握したい、使えるか判断したい場合にご活用下さい。デモをご希望の方は、下記よりお申込みいただけます。
![]()
