


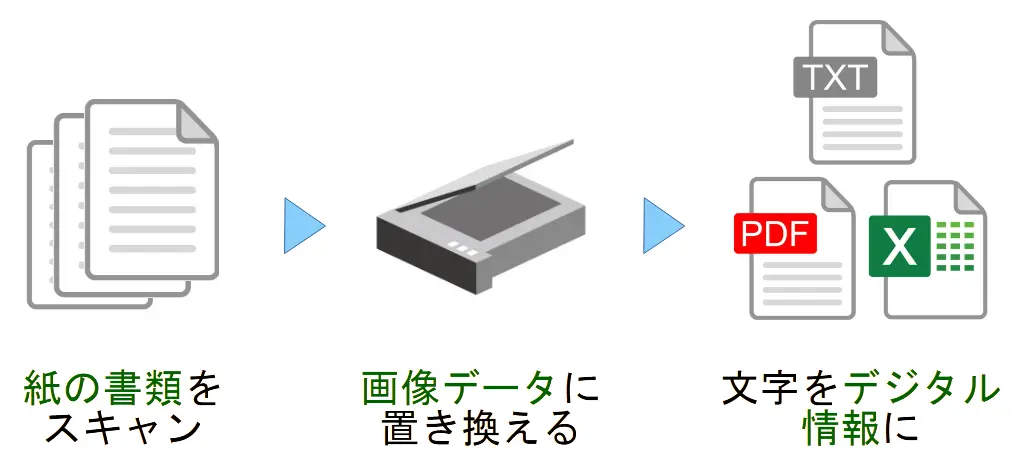
OCRとは
OCRとは、「Optical Character Recognition(光学文字認識)」の略で、紙や画像上にある文字情報をデジタルデータとして認識・読み取る技術のことである。具体的には、スキャナやカメラ、リーダーなどで読み取った文書や画像ファイルに含まれる文字を自動的に識別し、コンピュータが読み取り可能なテキスト形式に変換するものである。OCRは、印刷文字だけでなく、手書き文字の認識にも対応することができる。なお最近では、AI(人工知能)技術と組み合わせることによってさらに精度が向上している。
OCRが注目される背景
近年、ビジネスにおけるDX化やデジタル化が進む状況の中、OCRの技術は業務効率化、ペーパーレス化に効果が期待できるソリューションとして広がっている。特にペーパーレス化を促進する上でOCRは非常に大きな役割を果たしており、環境保全への取り組みや、働き方改革の一環としてテレワークやリモートワークへの対応にも貢献している。
また、2022年1月に改正された電子帳簿保存法では、業務や経理に必要な帳簿や書類などを、電子データで保存することを定めている。それまで紙で保管していた請求書や領収書などの帳票をデータ化するため、人間の手でデータ入力をする作業が必要となり、あらゆる業界の会社で対応に迫られた。こうした問題に対し、OCR機能で紙の書類を自動でデータ化することで手間や時間を削減することができ、法令への対応もしやすくなるため、そのメリットが大きく注目されるようになった。
OCRで文字を認識する仕組み
OCRの仕組みは、主に以下のようなプロセスに分かれて解析が行われる。4つのステップに分けてそれぞれ簡単に解説する。
1.画像のスキャン
まず最初に、画像ファイルやスキャンされたドキュメントから文字を認識するための事前準備が行われる。文字を識別する前に、あらかじめ画像の解像度を調整したり、ノイズを除去したりして、認識精度が上がるように画像のクオリティを改善する。
2.特徴抽出
次に、前処理が完了した画像から文字を識別するための「特徴抽出」が行われる。ここでは文字の形状や線の太さ、傾きなどを検出し、その文字が持つ特定のパターンや特徴を取得する。
3.文字認識
特徴が抽出されたら、次は「文字認識」を行う。OCRエンジンは、取得した複数の特徴を既存の文字パターンと照合し、どの文字に最も近いかを判別する。このプロセスで、手書きや印刷文字など異なるフォントに対応する認識精度が試される。
4.後処理
最後に、データに変換したテキストを、ExcelやWord、PDF、テキストデータ等のコンピュータで使えるファイルにして出力する。
以上のような一連のプロセスにより、画像上の文字をテキストデータとして扱うことができるようになる。
AI OCRとの違い
現在は、機械学習やディープラーニングを活用したOCRも登場しており、特にAIを用いた「AI OCR」では、より高精度な認識が可能になっている。通常のOCRの精度は、上記の仕組みで解説したように、登録されたパターンに依存している。特定のフォントや印刷文字に対しては高い精度を発揮する一方、手書き文字や特殊フォント、ノイズの多い画像では認識精度が低下することがある。
一方、AI OCR(AI-powered OCR)の文字認識技術では、従来のOCRにAIの人工知能技術を組み合わせている。画像中の文字の特徴を学習し、データのパターンをAIが継続的に分析することで、異なるフォントや筆跡、ノイズの多い画像でも高精度に認識できるように設計されている。そのため、従来のOCRに比べて柔軟で、様々なパターンの文字や手書き文字の認識精度を向上させることができる。
また、表やグラフ、画像が混在する複雑なレイアウトの文書でも、AIが読取領域や記載項目を自動抽出することができる。そのため、納品書や申請書などの様々なフォーマットの帳票でも、データを取り込むことが可能になるといった特徴がある。
OCRを導入するメリット
以下では、OCRを導入することで得られるメリットについて紹介する。
業務の効率化
OCRを導入することで、業務効率化とデータのデジタル化を大幅に進めることができる。従来の紙の書類を扱う業務では、手動での入力作業が多く、人手や時間が必要という課題があった。しかし、OCRを利用することで紙媒体からデジタルデータへの変換が自動化され、業務の高速化を実現することができる。実際に教育の現場では、手書きで記入された試験の答案用紙をOCR処理にて取り込み、自動採点を行うといったことも増えている。また、OCR機能でデータ化を自動化することによって、手入力の場合に比べて入力ミスや記入漏れが減り、データの正確性を高めることができる。そのため、目視でのチェックや修正作業にかかる手間を軽減することができる。
コストの削減
文書をOCRで読み込むことによってデータ化すれば、コピー用紙やインク代などの印刷コストを削減することができる。また、不要な書類原本を破棄することで、オフィスの物理的な保管場所の省スペース化にもつながるため、その分の管理・運用コストを削減することができる。
検索性の向上
OCRによって紙の書類や画像に含まれる文字情報がデジタルデータに変換されることで、データの検索性が大幅に向上する。例えば、必要な情報をキーワードで即座に検索できるようにすることで、膨大な書類の中から該当する項目を人が目視で確認して探す手間が省け、情報へのアクセスが容易に行える。特に大量の文書を扱う企業では、検索性が高まることで膨大な情報の中からデータを素早く引き出せるため、業務スピードの向上や迅速な意思決定にも貢献する。また、OCRによってデジタル化されたテキストデータは、検索エンジンやデータベースと連携しやすいため、社内での文書管理を効率よく進めることができるようになる。
書類修正の効率化
OCRを用いてデジタル化された文字列は、テキスト編集が可能になる点もメリットである。例えば、紙の契約書や報告書をデジタル化した後で内容に修正が必要な場合、デジタルデータなら直接編集ができるため、新たに書類を作成し直す必要がなくなる。これは特に、頻繁に更新が必要な書類やフォームなどにおいて有用である。また、修正したデータをそのままのフォーマットで再保存できるため、書類の最新状態を常に保つことができ、情報管理の精度が向上する。
OCR機能が使えるOSS
以下では、OCR機能を提供するOSSについて紹介する。
Tesseract
Tesseractは、OSSのOCRエンジンである。1985年にHP社によって開発が始まり、2005年にオープンソース化された後、Googleによって開発が行われた。
全文検索エンジンFessとTesseractの連携
Fessとは、CodeLibsというプロジェクトで開発されているオープンソース全文検索システムである。Webサイト内やファイルサーバ内のファイルに対し、高速な全文検索を行うことができる。また、さまざまな種類のファイル形式や検索方法に対応し、検索条件の絞り込みも行える。そのため、探したいファイルを瞬時に見つけることができる。専用のWebインタフェースからユーザやグループごとの閲覧権限を設定することも可能なため、本来見ることができないファイルが検索結果に表示されることを防ぎ、企業内でも全文検索を安心して使うことができる。
Fessは、高速な全文検索を実現するため、対象フォルダに定期的にアクセスしてファイルの内容を取得し、インデックスを生成する。このインデックス生成時にTesseractと連携することで、OCR技術で読み取ったPNGやPDF(画像)に含まれる文字情報も全文検索の対象とすることができる。デージーネットの調査結果では、1/4倍まで縮小コピーされた文書でも十分に読み取り可能であることが分かっており、紙の書類をスキャンした場合でも高い認識率で文字を検索することができる。ただし、手書きの文章の場合は認識率が低くなる可能性がある。
FessのOCR機能については、以下の記事で詳しくまとめて解説している。
デージーネットの取り組み
デージーネットでは、OCR機能を付加したFessの全文検索システムの構築サービスを行っている。Fessでは、検索対象のファイル数や容量が多くなると、チューニングが必要となったりクローリングに時間がかかったりすることから、システム構成やクローリング設定にも工夫が必要となる。デージーネットでは、システム構成やクローリング設定のほか、オンプレ型やクラウド型環境への対応など、お客様の用途やご要望に応じた最適な全文検索の環境を構築している。
また、弊社でシステムを構築したお客様に向けて、導入後の支援としてOpen Smart Assitanceと呼ばれる保守サポートも用意している。このサービスでは、例として使い方から運用方法まで幅広い範囲でのQ&Aの受け付けを行い、セキュリティ情報の提供、障害調査など、導入後も安心して利用して頂けるよう管理者の運用業務全体をサポートしている。
【Webセミナー】ゼロトラスト実装の始め方~OSS活用でコストを抑えて導入~
| 日程: | 4月23日(木)Webセミナー「BigBlueButton」を使用します。 |
| 内容: | 今回は、ゼロトラストの基本概念と求められる背景を整理したうえで、OSSを活用したゼロトラスト対策の実践的な進め方を解説します。 |
| ご興味のあるかたはぜひご参加ください。 | |
